My
earlier work on Streamlined NTRU Prime has been progressing along. The IETF document on
sntrup761 in SSH has passed several process points. GnuPG s
libgcrypt has added support for sntrup761. The
libssh support for sntrup761 is working, but the merge request is stuck mostly due to lack of time to debug why the regression test suite sporadically errors out in non-
sntrup761 related parts with the patch.
The foundation for
lattice-based post-quantum algorithms has some uncertainty around it, and I have felt that there is more to the post-quantum story than adding
sntrup761 to implementations.
Classic McEliece has been mentioned to me a couple of times, and I took some time to learn it and did a cut n paste job of the
proposed ISO standard and published
draft-josefsson-mceliece in the IETF to make the algorithm easily available to the IETF community. A high-quality implementation of Classic McEliece has been published as
libmceliece and I ve been supporting the work of Jan Moj to
package libmceliece for Debian, alas it has been stuck in the
ftp-master NEW queue for manual review for over two months. The pre-dependencies
librandombytes and
libcpucycles are available in Debian already.
All that text writing and packaging work set the scene to write some code. When I added support for
sntrup761 in
libssh, I became familiar with the
OpenSSH code base, so it was natural to return to OpenSSH to experiment with a new SSH KEX for Classic McEliece.
DJB suggested to pick
mceliece6688128 and combine it with the existing
X25519+sntrup761 or with plain
X25519. While a three-algorithm hybrid between
X25519,
sntrup761 and
mceliece6688128 would be a simple drop-in for those that don t want to lose the benefits offered by sntrup761, I decided to start the journey on a pure combination of
X25519 with
mceliece6688128. The key combiner in
sntrup761x25519 is a simple
SHA512 call and the only good I can say about that is that it is simple to describe and implement, and doesn t raise too many questions since it is already deployed.
After procrastinating coding for months, once I sat down to work it only took a couple of hours until I had a successful Classic McEliece SSH connection. I suppose my brain had sorted everything in background before I started. To reproduce it, please try the following in a Debian testing environment (I use
podman to get a clean environment).
# podman run -it --rm debian:testing-slim
apt update
apt dist-upgrade -y
apt install -y wget python3 librandombytes-dev libcpucycles-dev gcc make git autoconf libz-dev libssl-dev
cd ~
wget -q -O- https://lib.mceliece.org/libmceliece-20230612.tar.gz tar xfz -
cd libmceliece-20230612/
./configure
make install
ldconfig
cd ..
git clone https://gitlab.com/jas/openssh-portable
cd openssh-portable
git checkout jas/mceliece
autoreconf
./configure # verify 'libmceliece support: yes'
make # CC="cc -DDEBUG_KEX=1 -DDEBUG_KEXDH=1 -DDEBUG_KEXECDH=1"
You should now have a working SSH client and server that supports Classic McEliece! Verify support by running
./ssh -Q kex and it should mention
mceliece6688128x25519-sha512@openssh.com.
To have it print plenty of debug outputs, you may remove the
# character on the final line, but don t use such a build in production.
You can test it as follows:
./ssh-keygen -A # writes to /usr/local/etc/ssh_host_...
# setup public-key based login by running the following:
./ssh-keygen -t rsa -f ~/.ssh/id_rsa -P ""
cat ~/.ssh/id_rsa.pub > ~/.ssh/authorized_keys
adduser --system sshd
mkdir /var/empty
while true; do $PWD/sshd -p 2222 -f /dev/null; done &
./ssh -v -p 2222 localhost -oKexAlgorithms=mceliece6688128x25519-sha512@openssh.com date
On the client you should see output like this:
OpenSSH_9.5p1, OpenSSL 3.0.11 19 Sep 2023
...
debug1: SSH2_MSG_KEXINIT sent
debug1: SSH2_MSG_KEXINIT received
debug1: kex: algorithm: mceliece6688128x25519-sha512@openssh.com
debug1: kex: host key algorithm: ssh-ed25519
debug1: kex: server->client cipher: chacha20-poly1305@openssh.com MAC: <implicit> compression: none
debug1: kex: client->server cipher: chacha20-poly1305@openssh.com MAC: <implicit> compression: none
debug1: expecting SSH2_MSG_KEX_ECDH_REPLY
debug1: SSH2_MSG_KEX_ECDH_REPLY received
debug1: Server host key: ssh-ed25519 SHA256:YognhWY7+399J+/V8eAQWmM3UFDLT0dkmoj3pIJ0zXs
...
debug1: Host '[localhost]:2222' is known and matches the ED25519 host key.
debug1: Found key in /root/.ssh/known_hosts:1
debug1: rekey out after 134217728 blocks
debug1: SSH2_MSG_NEWKEYS sent
debug1: expecting SSH2_MSG_NEWKEYS
debug1: SSH2_MSG_NEWKEYS received
debug1: rekey in after 134217728 blocks
...
debug1: Sending command: date
debug1: pledge: fork
debug1: permanently_set_uid: 0/0
Environment:
USER=root
LOGNAME=root
HOME=/root
PATH=/usr/bin:/bin:/usr/sbin:/sbin:/usr/local/bin
MAIL=/var/mail/root
SHELL=/bin/bash
SSH_CLIENT=::1 46894 2222
SSH_CONNECTION=::1 46894 ::1 2222
debug1: client_input_channel_req: channel 0 rtype exit-status reply 0
debug1: client_input_channel_req: channel 0 rtype eow@openssh.com reply 0
Sat Dec 9 22:22:40 UTC 2023
debug1: channel 0: free: client-session, nchannels 1
Transferred: sent 1048044, received 3500 bytes, in 0.0 seconds
Bytes per second: sent 23388935.4, received 78108.6
debug1: Exit status 0
Notice the
kex: algorithm: mceliece6688128x25519-sha512@openssh.com output.
How about network bandwidth usage? Below is a comparison of a complete SSH client connection such as the one above that log in and print date and logs out. Plain
X25519 is around 7kb,
X25519 with
sntrup761 is around 9kb, and
mceliece6688128 with
X25519 is around 1MB. Yes, Classic McEliece has large keys, but for many environments, 1MB of data for the session establishment will barely be noticeable.
./ssh -v -p 2222 localhost -oKexAlgorithms=curve25519-sha256 date 2>&1 grep ^Transferred
Transferred: sent 3028, received 3612 bytes, in 0.0 seconds
./ssh -v -p 2222 localhost -oKexAlgorithms=sntrup761x25519-sha512@openssh.com date 2>&1 grep ^Transferred
Transferred: sent 4212, received 4596 bytes, in 0.0 seconds
./ssh -v -p 2222 localhost -oKexAlgorithms=mceliece6688128x25519-sha512@openssh.com date 2>&1 grep ^Transferred
Transferred: sent 1048044, received 3764 bytes, in 0.0 seconds
So how about session establishment time?
date; i=0; while test $i -le 100; do ./ssh -v -p 2222 localhost -oKexAlgorithms=curve25519-sha256 date > /dev/null 2>&1; i= expr $i + 1 ; done; date
Sat Dec 9 22:39:19 UTC 2023
Sat Dec 9 22:39:25 UTC 2023
# 6 seconds
date; i=0; while test $i -le 100; do ./ssh -v -p 2222 localhost -oKexAlgorithms=sntrup761x25519-sha512@openssh.com date > /dev/null 2>&1; i= expr $i + 1 ; done; date
Sat Dec 9 22:39:29 UTC 2023
Sat Dec 9 22:39:38 UTC 2023
# 9 seconds
date; i=0; while test $i -le 100; do ./ssh -v -p 2222 localhost -oKexAlgorithms=mceliece6688128x25519-sha512@openssh.com date > /dev/null 2>&1; i= expr $i + 1 ; done; date
Sat Dec 9 22:39:55 UTC 2023
Sat Dec 9 22:40:07 UTC 2023
# 12 seconds
I never noticed adding
sntrup761, so I m pretty sure I wouldn t notice this increase either. This is all running on
my laptop that runs Trisquel so take it with a grain of salt but at least the magnitude is clear.
Future work items include:
- Use a better hybrid mode combiner than SHA512? See for example KEM Combiners.
- Write IETF document describing the Classic McEliece SSH protocol
- Submit my patch to the OpenSSH community for discussion and feedback, please review meanwhile!
- Implement a mceliece6688128sntrup761x25519 multi-hybrid mode?
- Write a shell script a la sntrup761.sh to import a stripped-down mceliece6688128 implementation to avoid having OpenSSH depend on libmceliece?
- My kexmceliece6688128x25519.c is really just kexsntrup761x25519.c with the three calls to sntrup761 replaced with mceliece6688128. This should be parametrized to avoid cut n paste of code, if the OpenSSH community is interested.
- Consider if the behaviour of librandombytes related to closing of file descriptors is relevant to OpenSSH.
Happy post-quantum SSH ing!
Update: Changing the mceliece6688128_keypair call to mceliece6688128f_keypair (i.e., using the fully compatible f-variant) results in McEliece being just as fast as
sntrup761 on my machine.
Update 2023-12-26: An initial IETF document
draft-josefsson-ssh-mceliece-00 published.
 I think while developing Wayland-as-an-ecosystem we are now entrenched into narrow concepts of how a desktop should work. While discussing Wayland protocol additions, a lot of concepts clash, people from different desktops with different design philosophies debate the merits of those over and over again never reaching any conclusion (just as you will never get an answer out of humans whether sushi or pizza is the clearly superior food, or whether CSD or SSD is better). Some people want to use Wayland as a vehicle to force applications to submit to their desktop s design philosophies, others prefer the smallest and leanest protocol possible, other developers want the most elegant behavior possible. To be clear, I think those are all very valid approaches.
But this also creates problems: By switching to Wayland compositors, we are already forcing a lot of porting work onto toolkit developers and application developers. This is annoying, but just work that has to be done. It becomes frustrating though if Wayland provides toolkits with absolutely no way to reach their goal in any reasonable way. For Nate s Photoshop analogy: Of course Linux does not break Photoshop, it is Adobe s responsibility to port it. But what if Linux was missing a crucial syscall that Photoshop needed for proper functionality and Adobe couldn t port it without that? In that case it becomes much less clear on who is to blame for Photoshop not being available.
A lot of Wayland protocol work is focused on the environment and design, while applications and work to port them often is considered less. I think this happens because the overlap between application developers and developers of the desktop environments is not necessarily large, and the overlap with people willing to engage with Wayland upstream is even smaller. The combination of Windows developers porting apps to Linux and having involvement with toolkits or Wayland is pretty much nonexistent. So they have less of a voice.
I think while developing Wayland-as-an-ecosystem we are now entrenched into narrow concepts of how a desktop should work. While discussing Wayland protocol additions, a lot of concepts clash, people from different desktops with different design philosophies debate the merits of those over and over again never reaching any conclusion (just as you will never get an answer out of humans whether sushi or pizza is the clearly superior food, or whether CSD or SSD is better). Some people want to use Wayland as a vehicle to force applications to submit to their desktop s design philosophies, others prefer the smallest and leanest protocol possible, other developers want the most elegant behavior possible. To be clear, I think those are all very valid approaches.
But this also creates problems: By switching to Wayland compositors, we are already forcing a lot of porting work onto toolkit developers and application developers. This is annoying, but just work that has to be done. It becomes frustrating though if Wayland provides toolkits with absolutely no way to reach their goal in any reasonable way. For Nate s Photoshop analogy: Of course Linux does not break Photoshop, it is Adobe s responsibility to port it. But what if Linux was missing a crucial syscall that Photoshop needed for proper functionality and Adobe couldn t port it without that? In that case it becomes much less clear on who is to blame for Photoshop not being available.
A lot of Wayland protocol work is focused on the environment and design, while applications and work to port them often is considered less. I think this happens because the overlap between application developers and developers of the desktop environments is not necessarily large, and the overlap with people willing to engage with Wayland upstream is even smaller. The combination of Windows developers porting apps to Linux and having involvement with toolkits or Wayland is pretty much nonexistent. So they have less of a voice.

 I will also bring my two protocol MRs to their conclusion for sure, because as application developers we need clarity on what the platform (either all desktops or even just a few) supports and will or will not support in future. And the only way to get something good done is by contribution and friendly discussion.
I will also bring my two protocol MRs to their conclusion for sure, because as application developers we need clarity on what the platform (either all desktops or even just a few) supports and will or will not support in future. And the only way to get something good done is by contribution and friendly discussion.

 I ve mentioned this in a
I ve mentioned this in a
 CW for body size change mentions
I needed a corset, badly.
Years ago I had a chance to have my measurements taken by a former
professional corset maker and then a lesson in how to draft an underbust
corset, and that lead to me learning how nice wearing a well-fitted
corset feels.
Later I tried to extend that pattern up for a midbust corset, with
success.
And then my body changed suddenly, and I was no longer able to wear
either of those, and after a while I started missing them.
Since my body was still changing (if no longer drastically so), and I
didn t want to use expensive materials for something that had a risk of
not fitting after too little time, I decided to start by making myself a
summer lightweight corset in aida cloth and plastic boning (for which I
had already bought materials). It fitted, but not as well as the first
two ones, and I ve worn it quite a bit.
I still wanted back the feeling of wearing a comfy, heavy contraption of
coutil and steel, however.
After a lot of procrastination I redrafted a new pattern, scrapped
everything, tried again, had my measurements taken by a dressmaker
[#dressmaker], put them in the draft, cut a first mock-up in cheap
cotton, fixed the position of a seam, did a second mock-up in denim
[#jeans] from an old pair of jeans, and then cut into the cheap
herringbone coutil I was planning to use.
And that s when I went to see which one of the busks in my stash would
work, and realized that I had used a wrong vertical measurement and the
front of the corset was way too long for a midbust corset.
CW for body size change mentions
I needed a corset, badly.
Years ago I had a chance to have my measurements taken by a former
professional corset maker and then a lesson in how to draft an underbust
corset, and that lead to me learning how nice wearing a well-fitted
corset feels.
Later I tried to extend that pattern up for a midbust corset, with
success.
And then my body changed suddenly, and I was no longer able to wear
either of those, and after a while I started missing them.
Since my body was still changing (if no longer drastically so), and I
didn t want to use expensive materials for something that had a risk of
not fitting after too little time, I decided to start by making myself a
summer lightweight corset in aida cloth and plastic boning (for which I
had already bought materials). It fitted, but not as well as the first
two ones, and I ve worn it quite a bit.
I still wanted back the feeling of wearing a comfy, heavy contraption of
coutil and steel, however.
After a lot of procrastination I redrafted a new pattern, scrapped
everything, tried again, had my measurements taken by a dressmaker
[#dressmaker], put them in the draft, cut a first mock-up in cheap
cotton, fixed the position of a seam, did a second mock-up in denim
[#jeans] from an old pair of jeans, and then cut into the cheap
herringbone coutil I was planning to use.
And that s when I went to see which one of the busks in my stash would
work, and realized that I had used a wrong vertical measurement and the
front of the corset was way too long for a midbust corset.
 Luckily I also had a few longer busks, I basted one to the denim mock up
and tried to wear it for a few hours, to see if it was too long to be
comfortable. It was just a bit, on the bottom, which could be easily
fixed with the Power Tools
Luckily I also had a few longer busks, I basted one to the denim mock up
and tried to wear it for a few hours, to see if it was too long to be
comfortable. It was just a bit, on the bottom, which could be easily
fixed with the Power Tools I could have been a bit more precise with the binding, as it doesn t
align precisely at the front edge, but then again, it s underwear,
nobody other than me and everybody who reads this post is going to see
it and I was in a hurry to see it finished. I will be more careful with
the next one.
I could have been a bit more precise with the binding, as it doesn t
align precisely at the front edge, but then again, it s underwear,
nobody other than me and everybody who reads this post is going to see
it and I was in a hurry to see it finished. I will be more careful with
the next one.
 I also think that I haven t been careful enough when pressing the seams
and applying the tape, and I ve lost about a cm of width per part, so
I m using a lacing gap that is a bit wider than I planned for, but that
may change as the corset gets worn, and is still within tolerance.
Also, on the morning after I had finished the corset I woke up and
realized that I had forgotten to add garter tabs at the bottom edge.
I don t know whether I will ever use them, but I wanted the option, so
maybe I ll try to add them later on, especially if I can do it without
undoing the binding.
The next step would have been flossing, which I proceeded to postpone
until I ve worn the corset for a while: not because there is any reason
for it, but because I still don t know how I want to do it :)
What was left was finishing and uploading the
I also think that I haven t been careful enough when pressing the seams
and applying the tape, and I ve lost about a cm of width per part, so
I m using a lacing gap that is a bit wider than I planned for, but that
may change as the corset gets worn, and is still within tolerance.
Also, on the morning after I had finished the corset I woke up and
realized that I had forgotten to add garter tabs at the bottom edge.
I don t know whether I will ever use them, but I wanted the option, so
maybe I ll try to add them later on, especially if I can do it without
undoing the binding.
The next step would have been flossing, which I proceeded to postpone
until I ve worn the corset for a while: not because there is any reason
for it, but because I still don t know how I want to do it :)
What was left was finishing and uploading the  Debian Public Statement about the EU Cyber Resilience Act and the Product Liability Directive
The European Union is currently preparing a regulation "on horizontal
cybersecurity requirements for products with digital elements" known as the
Cyber Resilience Act (CRA). It is currently in the final "trilogue" phase of
the legislative process. The act includes a set of essential cybersecurity and
vulnerability handling requirements for manufacturers. It will require products
to be accompanied by information and instructions to the user. Manufacturers
will need to perform risk assessments and produce technical documentation and,
for critical components, have third-party audits conducted. Discovered security
issues will have to be reported to European authorities within 25 hours (1).
The CRA will be followed up by the Product Liability Directive (PLD) which will
introduce compulsory liability for software.
While a lot of these regulations seem reasonable, the Debian project believes
that there are grave problems for Free Software projects attached to them.
Therefore, the Debian project issues the following statement:
Debian Public Statement about the EU Cyber Resilience Act and the Product Liability Directive
The European Union is currently preparing a regulation "on horizontal
cybersecurity requirements for products with digital elements" known as the
Cyber Resilience Act (CRA). It is currently in the final "trilogue" phase of
the legislative process. The act includes a set of essential cybersecurity and
vulnerability handling requirements for manufacturers. It will require products
to be accompanied by information and instructions to the user. Manufacturers
will need to perform risk assessments and produce technical documentation and,
for critical components, have third-party audits conducted. Discovered security
issues will have to be reported to European authorities within 25 hours (1).
The CRA will be followed up by the Product Liability Directive (PLD) which will
introduce compulsory liability for software.
While a lot of these regulations seem reasonable, the Debian project believes
that there are grave problems for Free Software projects attached to them.
Therefore, the Debian project issues the following statement:
 This is a post I wrote in June 2022, but did not publish back then.
After first publishing it in December 2023, a perfectionist insecure
part of me unpublished it again. After receiving positive feedback, i
slightly amended and republish it now.
In this post, I talk about unpaid work in F/LOSS, taking on the example
of hackathons, and why, in my opinion, the expectation of volunteer work
is hurting diversity.
Disclaimer: I don t have all the answers, only some ideas and questions.
This is a post I wrote in June 2022, but did not publish back then.
After first publishing it in December 2023, a perfectionist insecure
part of me unpublished it again. After receiving positive feedback, i
slightly amended and republish it now.
In this post, I talk about unpaid work in F/LOSS, taking on the example
of hackathons, and why, in my opinion, the expectation of volunteer work
is hurting diversity.
Disclaimer: I don t have all the answers, only some ideas and questions.








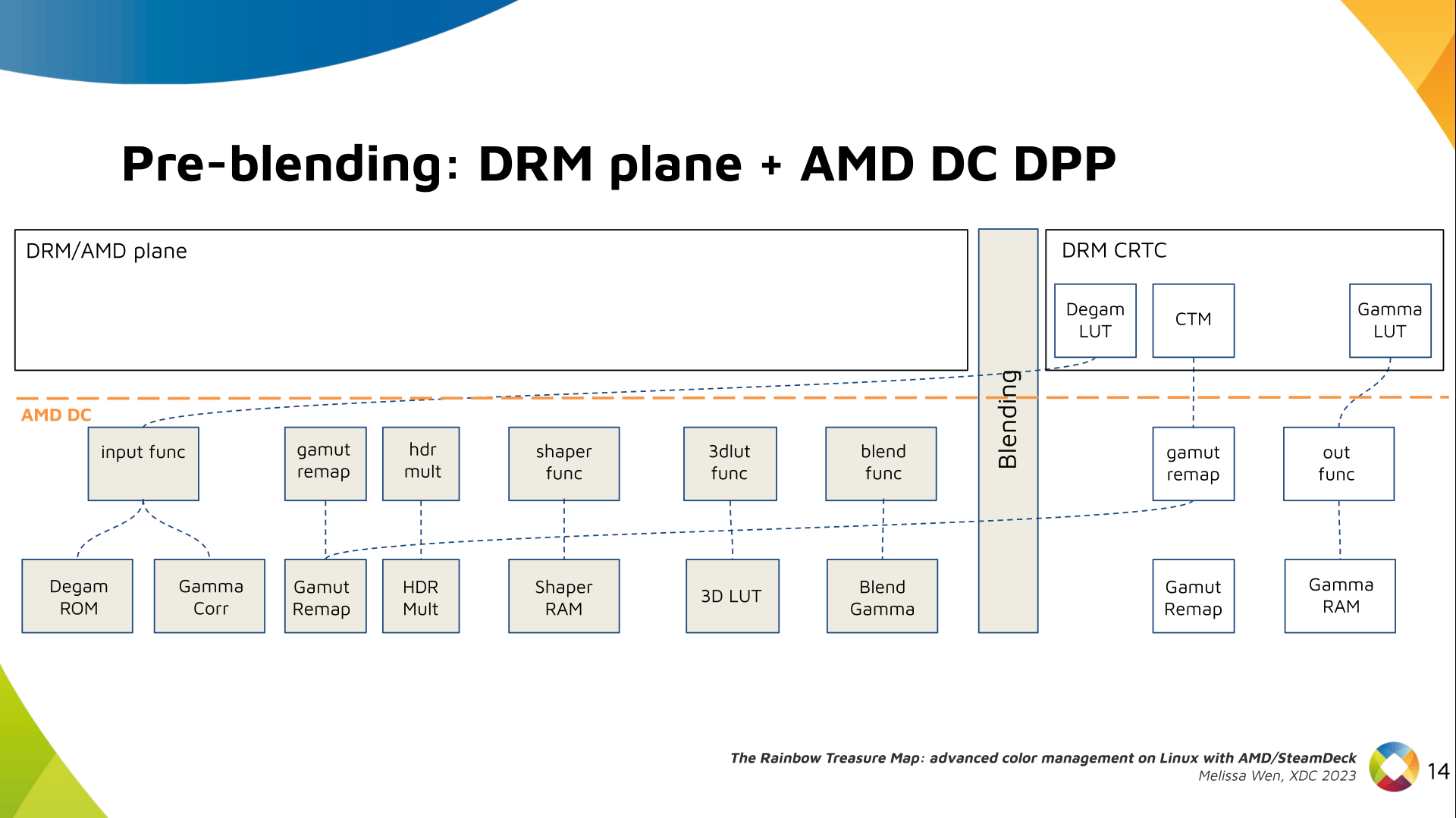
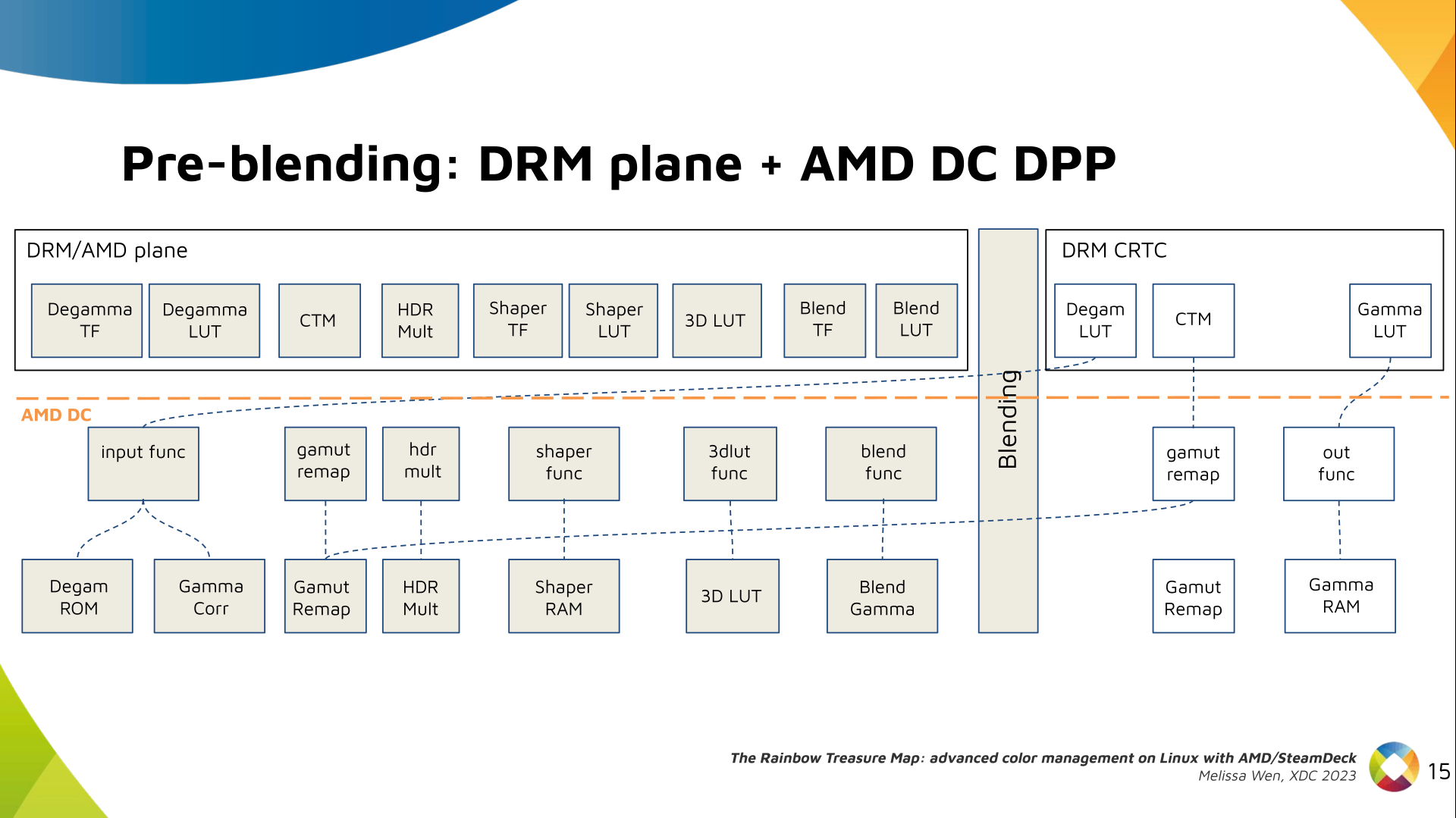
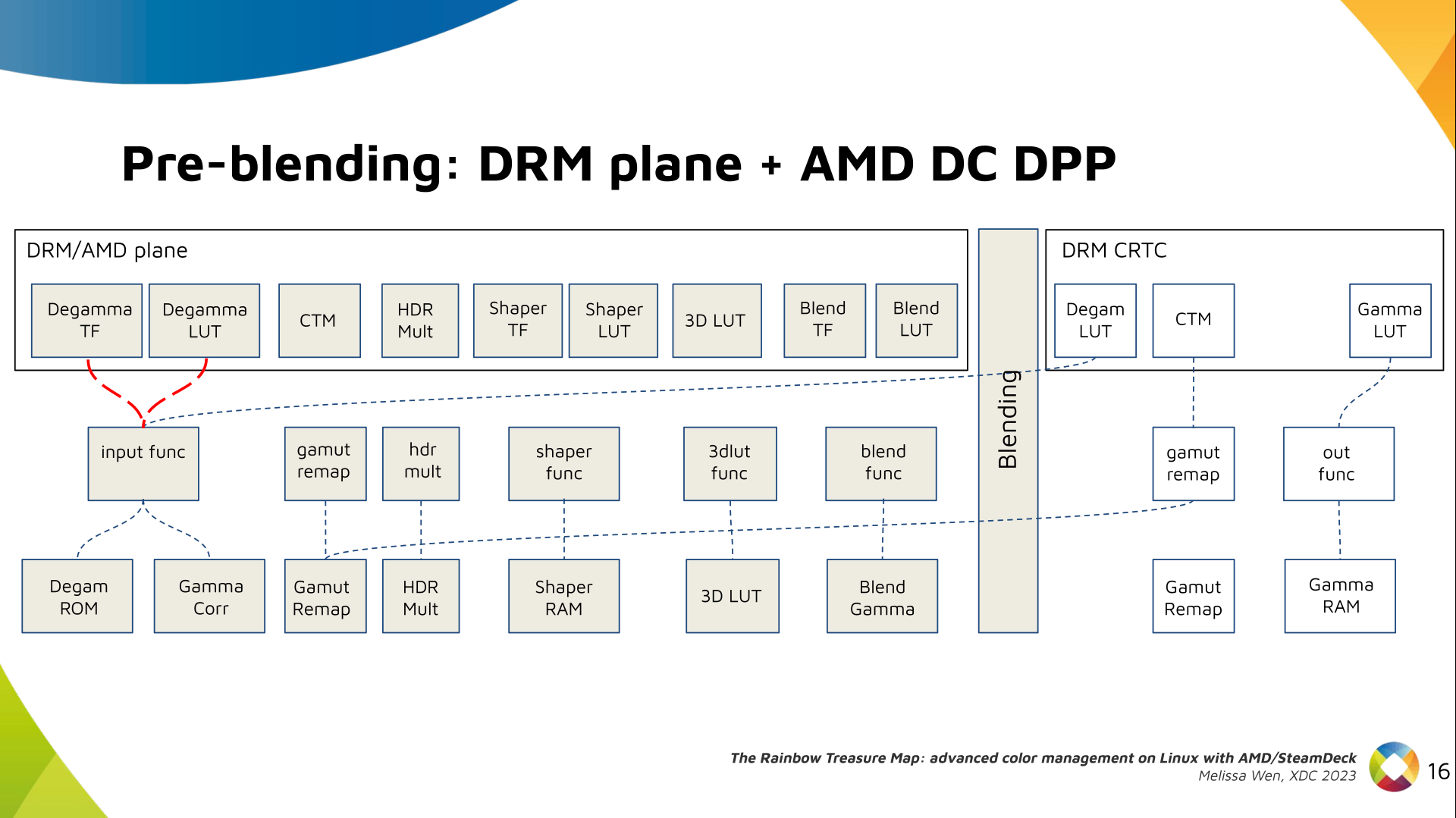

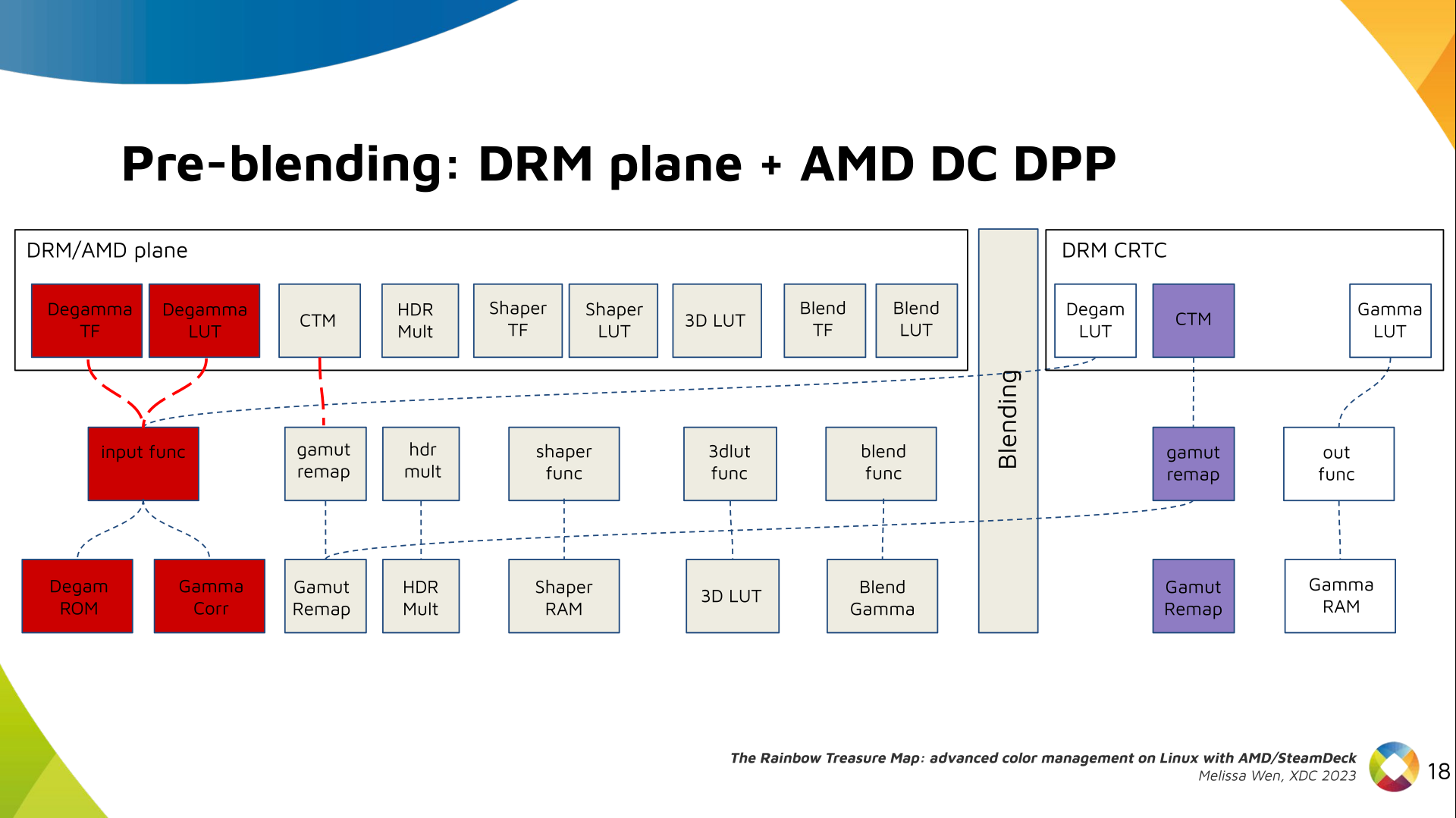

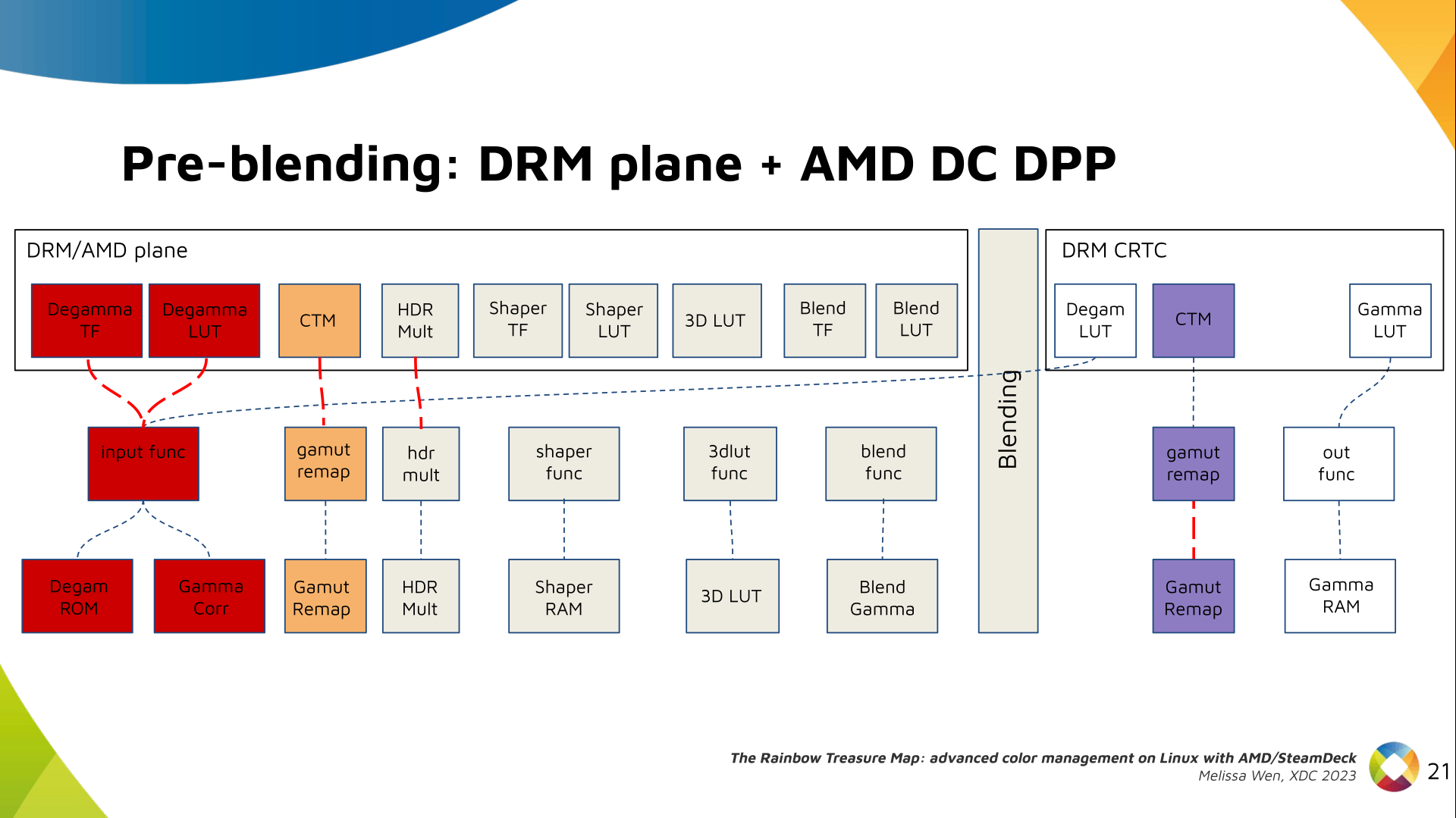

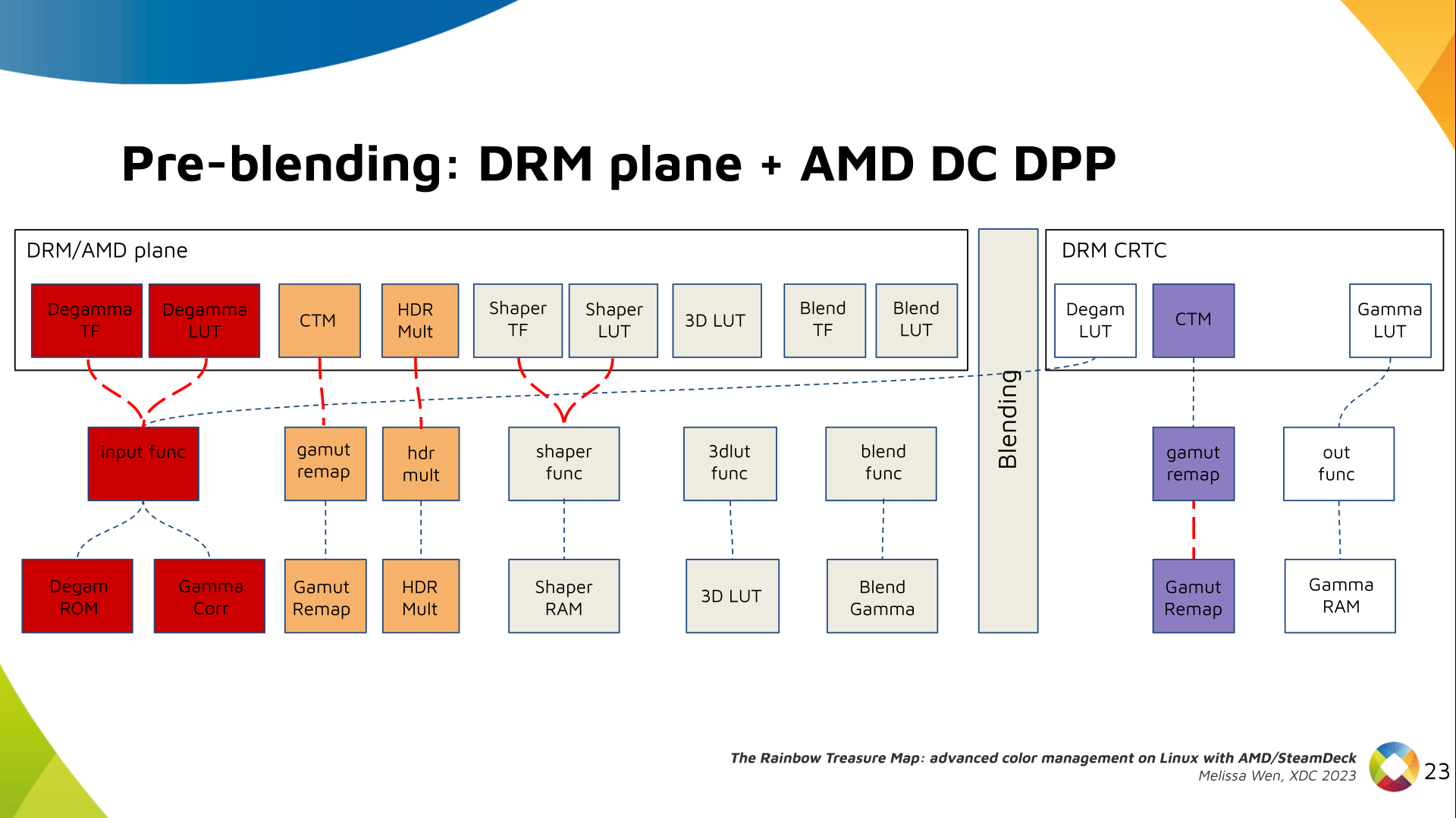

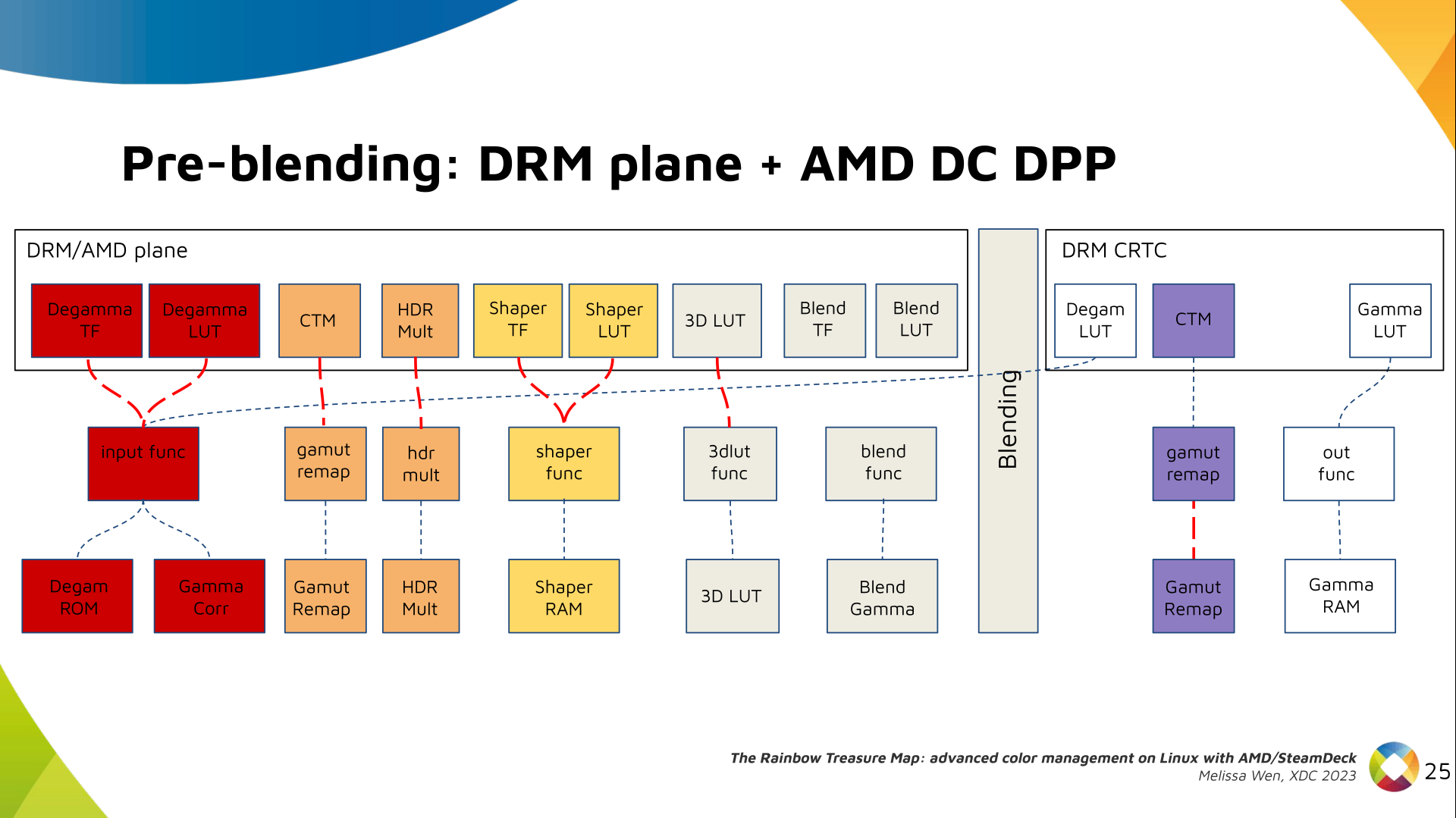

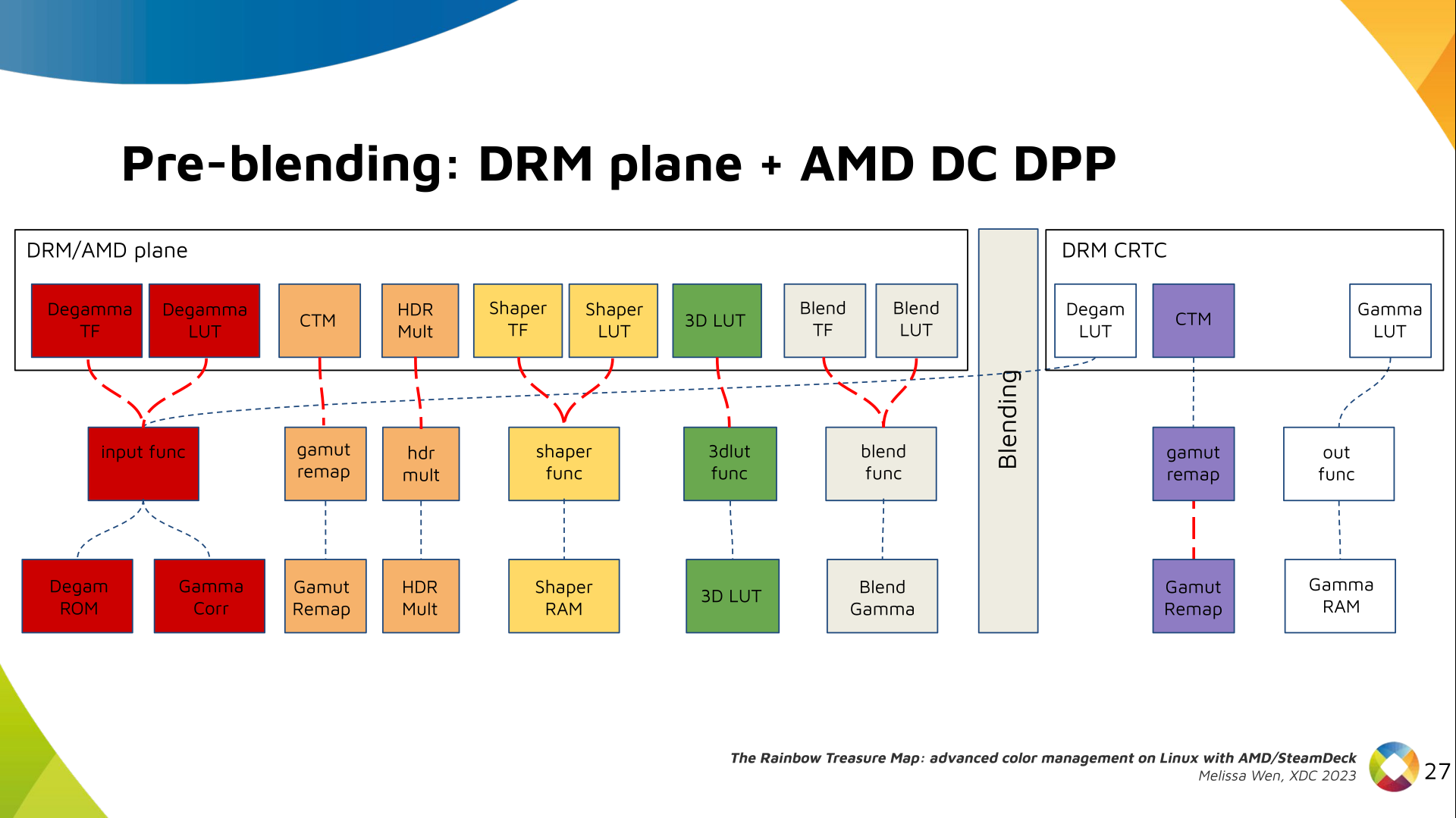

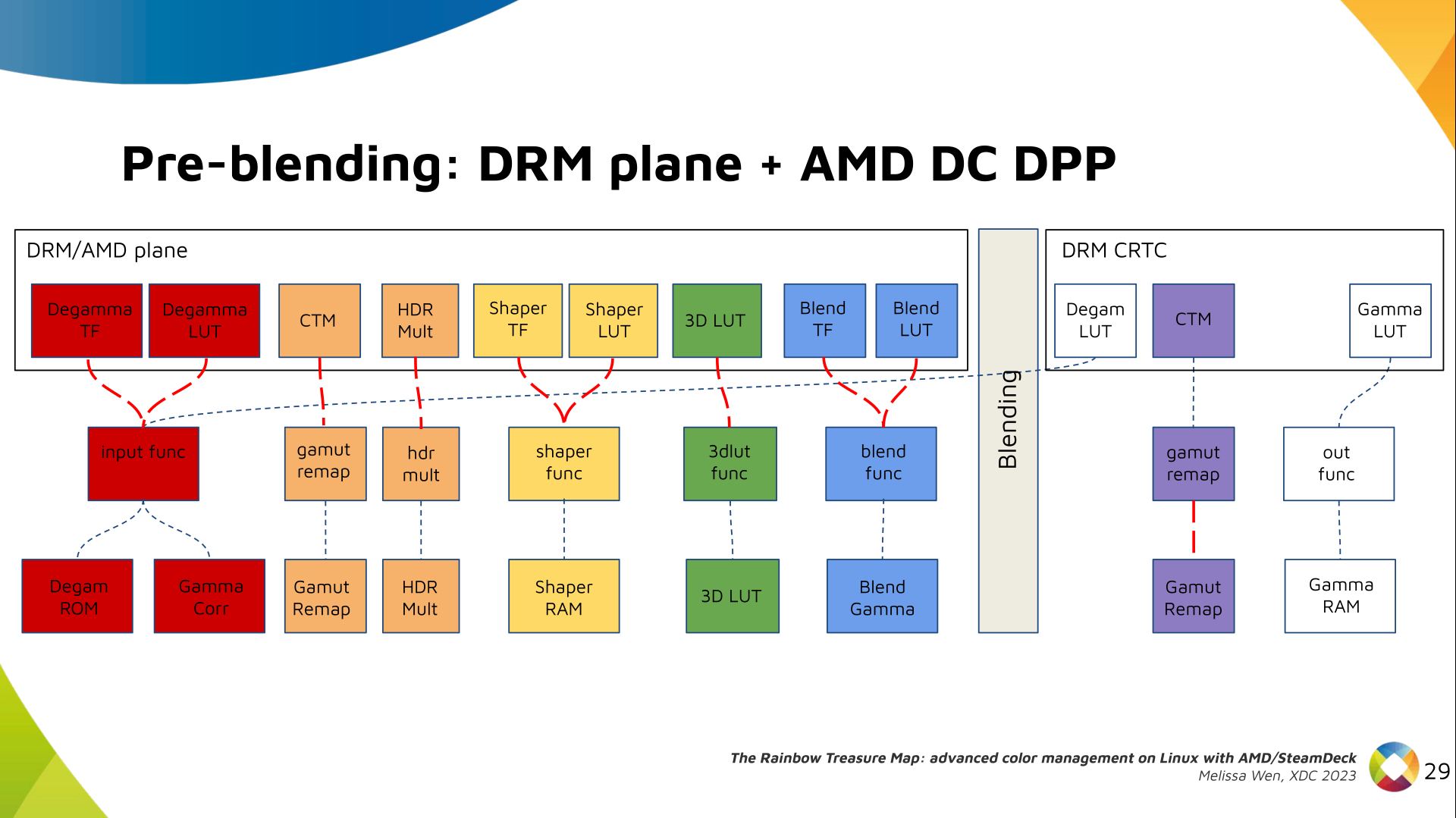
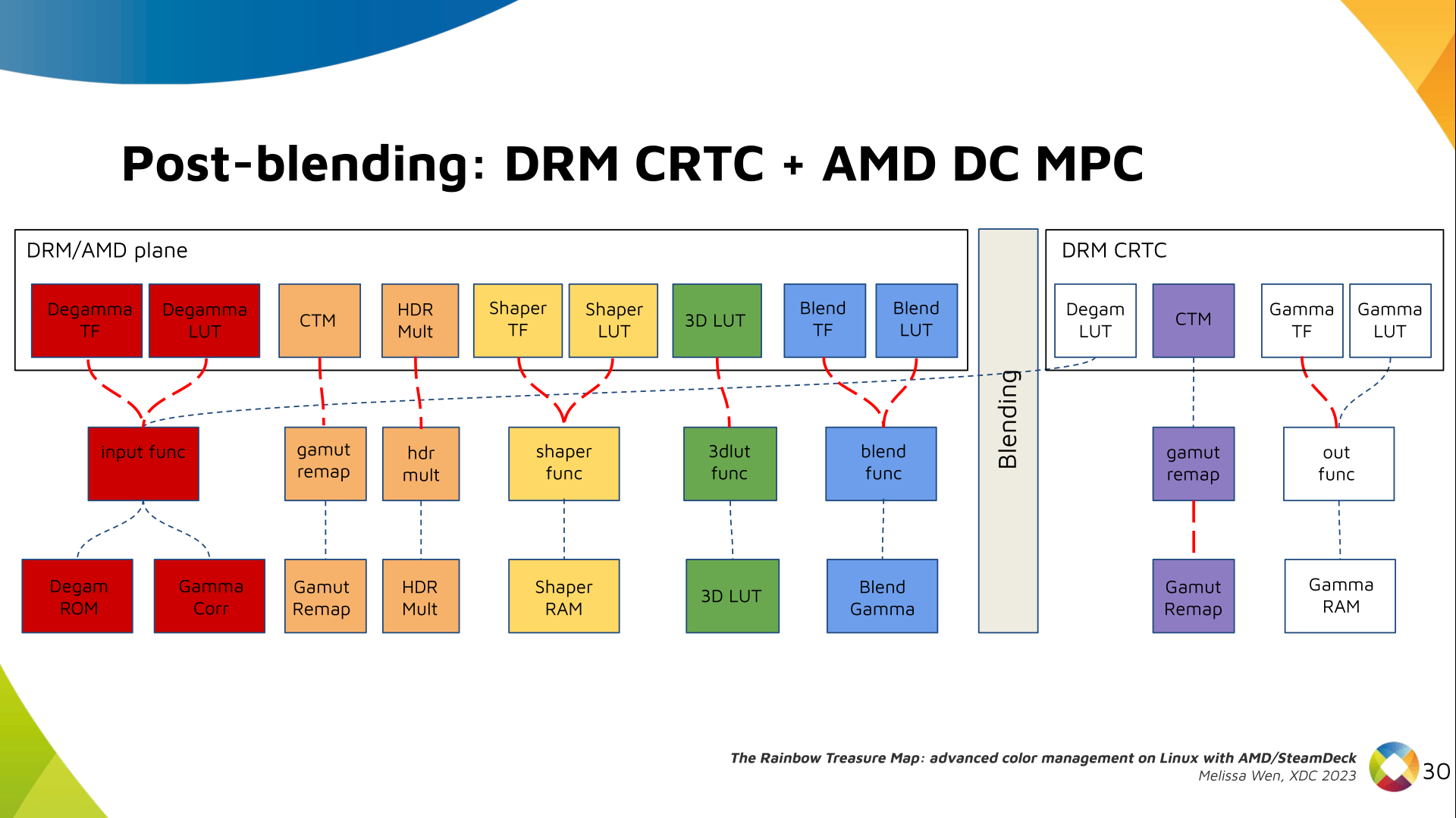

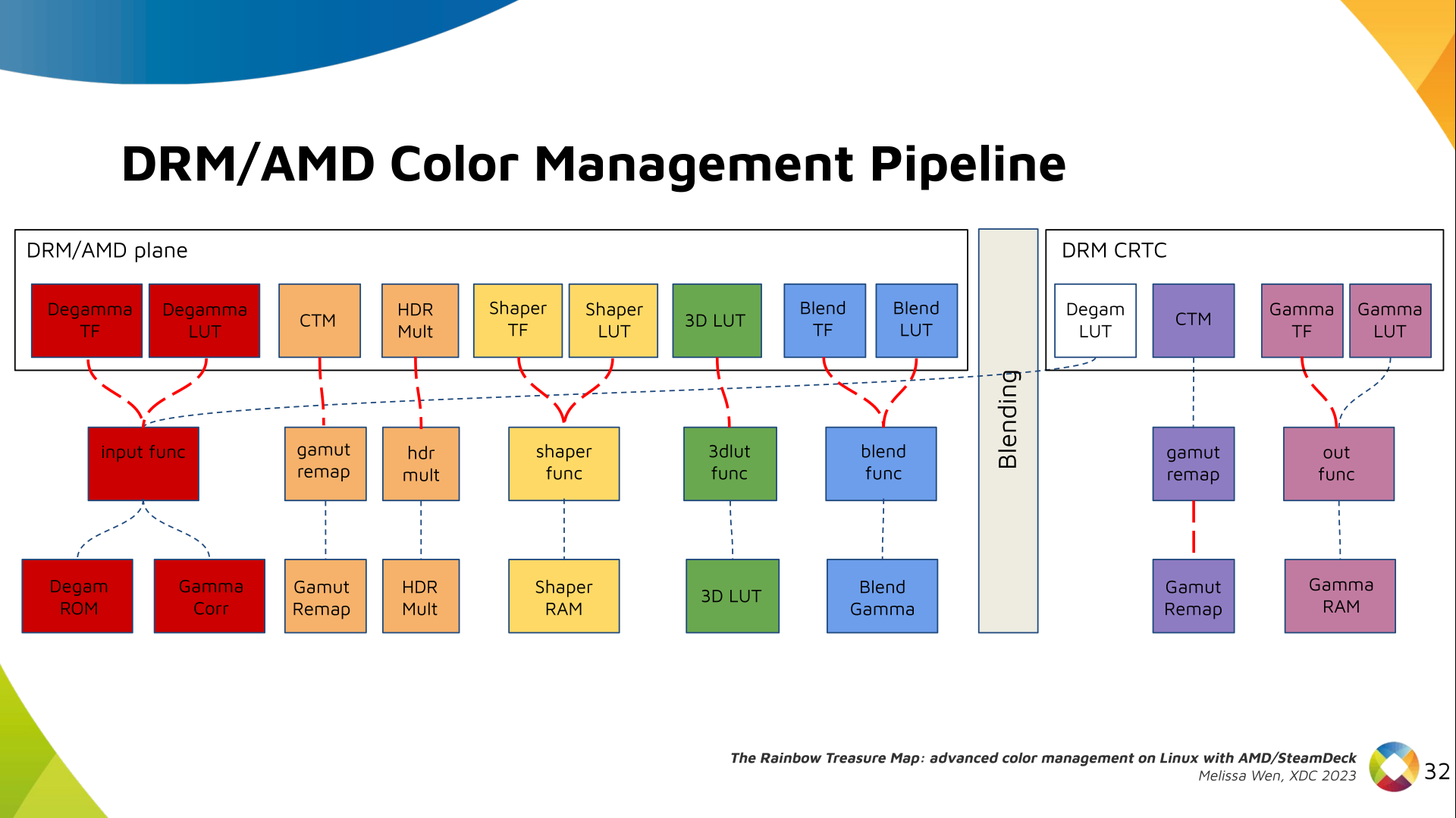
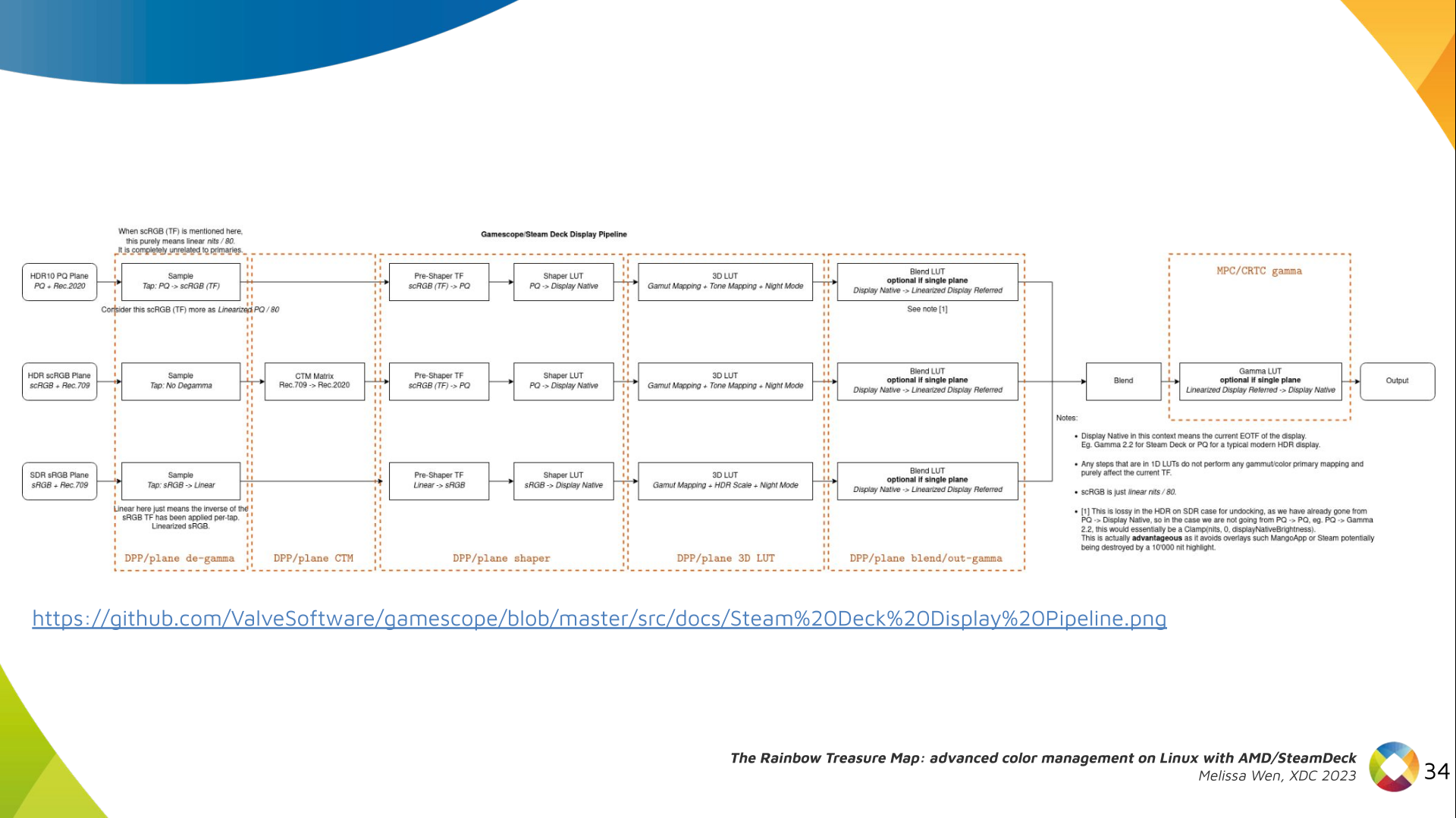

 Now, I think it's safe to assume this program is dead and buried, and
anyways I'm running
Now, I think it's safe to assume this program is dead and buried, and
anyways I'm running  For multi-monitor setups,
For multi-monitor setups,  Some years ago a customer needed a live ISO containing a customized
FAI environment (not for installing but for extended hardware stress
tests), but on an USB stick with the possibility to store the logs of
the tests on the USB stick. But an ISO file system (iso9660) remains
read-only, even when put onto an USB stick.
I had the idea to add another partition onto the USB stick after
the ISO was written to it (using cp or dd).
You can use fdisk with an ISO file, add a new partition, loop mount
the ISO and format this partition. That's all. This worked perfect for my customer.
I forgot this idea for a while but a few weeks ago I remembered it.
What could be possible when my FAI (Fully Automatic Installation)
image would also provide such a partition? Which things could be
provided on this partition?
Could I provide a FAI ISO and my users would be able to easily put
their own .deb package onto it without remastering the ISO or building
an ISO on their own?
Now here's the shell script, that extends an ISO or an USB stick with an
ext4 or exFAT partition and set the file system label to MY-DATA.
Some years ago a customer needed a live ISO containing a customized
FAI environment (not for installing but for extended hardware stress
tests), but on an USB stick with the possibility to store the logs of
the tests on the USB stick. But an ISO file system (iso9660) remains
read-only, even when put onto an USB stick.
I had the idea to add another partition onto the USB stick after
the ISO was written to it (using cp or dd).
You can use fdisk with an ISO file, add a new partition, loop mount
the ISO and format this partition. That's all. This worked perfect for my customer.
I forgot this idea for a while but a few weeks ago I remembered it.
What could be possible when my FAI (Fully Automatic Installation)
image would also provide such a partition? Which things could be
provided on this partition?
Could I provide a FAI ISO and my users would be able to easily put
their own .deb package onto it without remastering the ISO or building
an ISO on their own?
Now here's the shell script, that extends an ISO or an USB stick with an
ext4 or exFAT partition and set the file system label to MY-DATA.

 An exciting new release 0.4.21 of
An exciting new release 0.4.21 of 


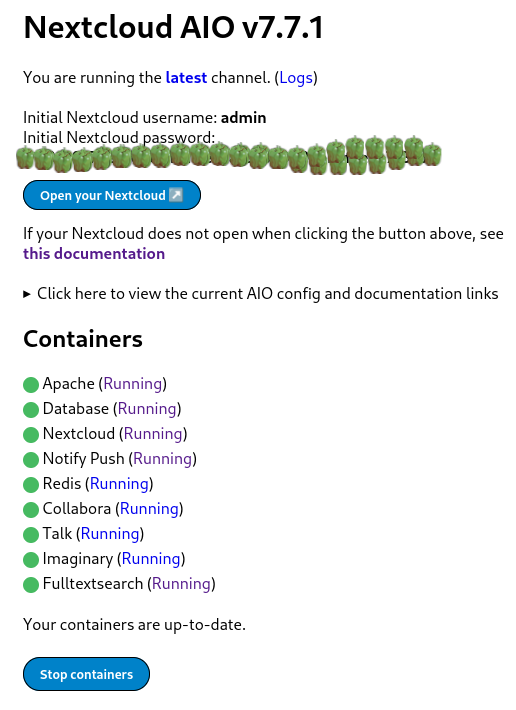
 Nextcloud is a popular self-hosted solution for file sync and share as well as cloud apps such as document editing, chat and talk, calendar, photo gallery etc. This guide will walk you through setting up Nextcloud AIO using Docker Compose. This blog post would not be possible without immense help from Sahil Dhiman a.k.a.
Nextcloud is a popular self-hosted solution for file sync and share as well as cloud apps such as document editing, chat and talk, calendar, photo gallery etc. This guide will walk you through setting up Nextcloud AIO using Docker Compose. This blog post would not be possible without immense help from Sahil Dhiman a.k.a. 



 For reasons I won't go into right now, I've spent some of this year
working on a refurbished Lenovo Thinkpad Yoga 260. Despite it being
relatively underpowered, I love almost everything about it.
Unfortunately the model I bought has 8G RAM which turned out to be
more limiting than I thought it would be. You can do incredible
things with 8G of RAM: incredible, wondrous things. And most of
my work, whether that's wrangling containers, hacking on OpenJDK, or
complex Haskell projects, are manageable.
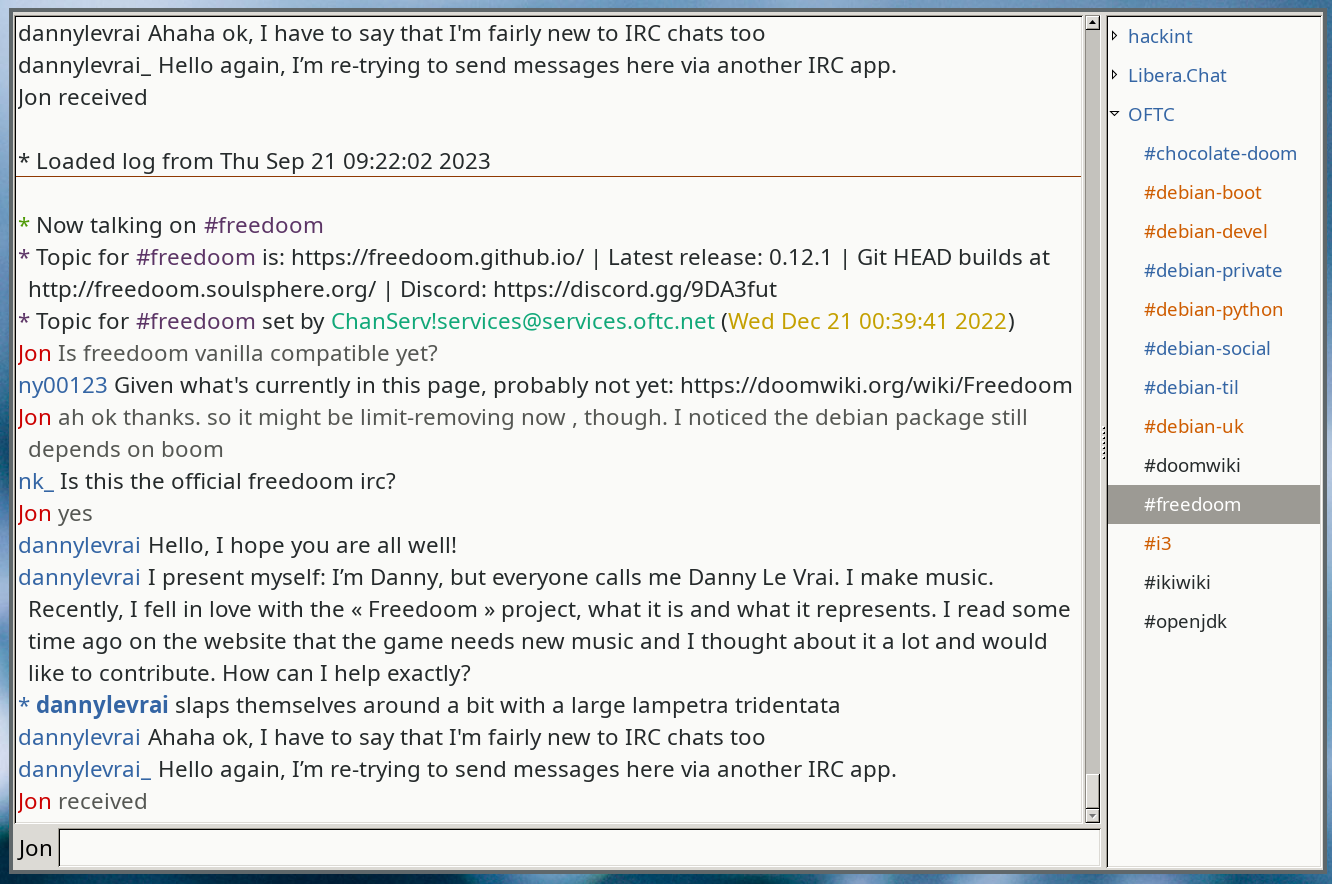
Where it falls down is driving the modern scourge: Electron, and by
proxy, lots of modern IM tools: Slack (urgh), Discord (where one of
my main IRC social communities moved to), WhatsApp Web
For reasons I won't go into right now, I've spent some of this year
working on a refurbished Lenovo Thinkpad Yoga 260. Despite it being
relatively underpowered, I love almost everything about it.
Unfortunately the model I bought has 8G RAM which turned out to be
more limiting than I thought it would be. You can do incredible
things with 8G of RAM: incredible, wondrous things. And most of
my work, whether that's wrangling containers, hacking on OpenJDK, or
complex Haskell projects, are manageable.
Where it falls down is driving the modern scourge: Electron, and by
proxy, lots of modern IM tools: Slack (urgh), Discord (where one of
my main IRC social communities moved to), WhatsApp Web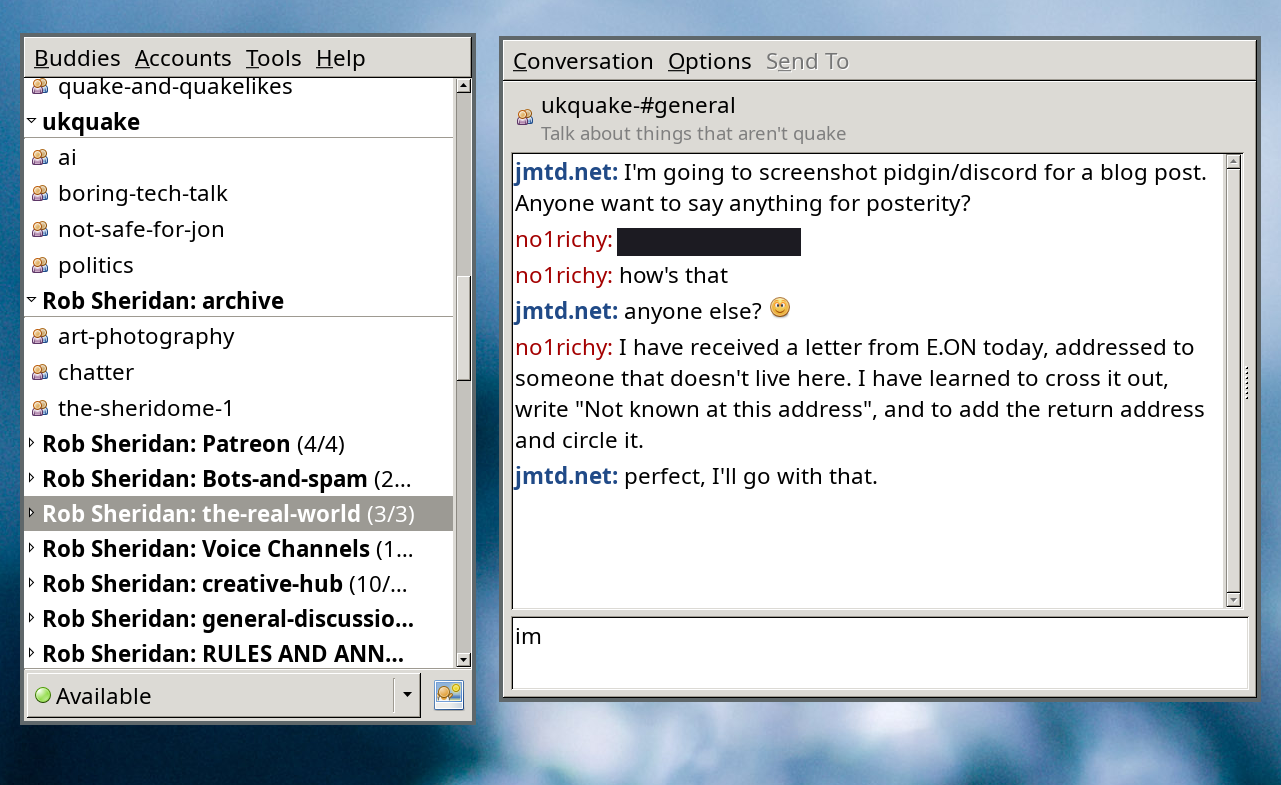
{kind=link}